这篇文章转载自我在知乎的文章
最近在学习机器学习相关知识,在学习的过程中有一些自己的心得体会,在此做了个学习总结,方便查阅,也给想了解机器学习或者Python的同学提供一点点帮助。
科普
机器学习(Machine Learning)专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合。 ——百度百科
简单的讲,机器学习就是一门让机器能够进行自我学习并不断优化功能的学科。
本篇分算法原理和代码实现来介绍k-近邻算法。(下文会涉及算法解析和部分专业术语,需要一定的Python语言和算法基础)
算法原理
k-近邻(k-Nearest Neighbour,简称KNN),常用于有监督学习。
KNN的工作原理很简单:存在一个训练样本集合A,在给定测试样本b时,基于某种距离度量,找出训练集A中与测试样本b最靠近的k个训练样本(通常k≤20且为整数),之后,基于这k个训练样本的信息来预测种类或值。
其中,在分类问题中,KNN用来预测种类。一般使用“投票法”,选择这k个样本中出现最多的类别来作为测试样本的类别。
在回归问题中,KNN预测一个值。使用“平均法”,将k个样本的实值输出的平均值作为测试样本的输出。一般情况下,距离度量选择欧式距离:
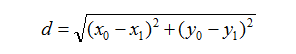
三维的欧式距离公式为:
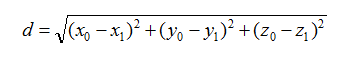
其他维度以此类推。
举个例子
假设:评价一个人的长相用 [“好看”,“中等”,“难看”]来衡量。评价人的特征用:身高、体重、年龄。我们已有一个200*4的数据集合矩阵作为训练样本,矩阵的4列分别为:身高、体重、年龄、长相。
现得到一个测试样本,包括身高、体重、年龄三个评价特征,这时我们用KNN对这个人的长相进行分类。
伪代码如下:
对测试样本点进行以下操作:
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前点距离最小的k个点;
(4)确定前k个点所在类别的出现频率;
(5)返回前k个点出现频率最高的类别作为当前点的预测分类。
1.算法的泛化误差
KNN算法虽然很简单,但是其泛化误差(算法推广后,机器对于未知数据的学习错误率)却是可以接受,以1NN问题(即k=1)为例,推导过程如下:
给定测试样本x,若其最近邻样本为z,1NN出错率就是x与z类别标记不同的概率,即:
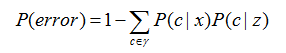
假设样本独立同分布,且对任意x和任意小正数d,在x附近d距离范围内总能找到一个训练样本z,令
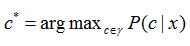
表示贝叶斯最优分类器(以最小化总体风险为目标,对于样本的分类。通俗讲就是样本最好的分类方式,具体推导见周志华老师《机器学习》的P147页)的结果。
此时有:
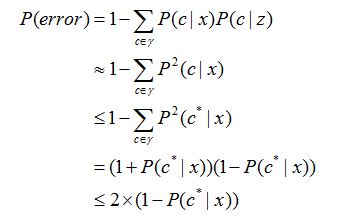
以上得出,1NN的结构不仅简单,而且1NN的泛化错误率≤2倍的贝叶斯最优分类器错误率。
2.算法的不足
KNN算法作为一种较简单的算法,它的不足之处在于:
(1)没有明显的训练过程,它是“懒惰学习”的典型代表,它在训练阶段所做的仅仅是将样本保存起来,如果训练集很大,必须使用大量的存储空间,训练时间开销为零;
(2)必须对数据集中每个数据计算距离值,实际中可能非常耗时。
3.kd树
由于上述的不足,为了提高KNN搜索的速度,可以利用特殊的数据存储形式来减少计算距离的次数。kd树就是一种以二叉树的形式存储数据的方法。
kd树就是对k维空间的一个划分。构造kd树相当于不断用垂直于坐标轴的超平面将k维空间切分,构成一系列k维超矩阵区域。kd树的每一个节点对应一个超矩阵区域。(想要深入了解的同学可以参看李航老师的《统计机器学习》P41页)
举个例子
给定一个二维空间的数据集:
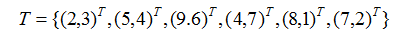
请构造一个平衡kd树(平衡kd树就是以中位数作为划分标准)。
解:根据点对应包含数据集T的矩阵,选择x1轴,6个数据点的x1坐标的中位数是7,以平面x1=7将空间分为左、右两个子矩阵(子节点)。
接着,左矩阵形以x2=4分为两个子矩阵,右矩阵形以x2=6分为两个子矩阵。
如此递归,最后得到如下图所示的特征空间划分。
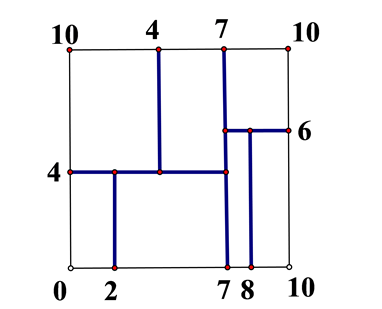
形成kd树,并利用kd树进行KNN搜索。搜索时从叶子节点往根节点搜索,具体搜索过程不展开赘述。
代码实现与解读
现在机器学习的很多基础算法都能调用scikit-learn中的包来实现,可能只需要一行命令。但我还是希望我们能够自己动手实现一遍里面的算法,会加深自己对于算法的理解。
下面的代码部分主要源于《机器学习实战》,书中对于代码部分并未做太多解释,对于Python初学者来说不太很友好,所以我加上了更详细的解释,方便初学者学习。
1. k-近邻算法
这是算法比较核心的地方,也是上述伪代码具体的实现。
程序清单:


2. 将文本数据转换为矩阵
我们在本地存储的训练集样本多为CSV格式或TXT格式,而若要在计算机中对它们进行处理,首先得将它们转换为矩阵形式。
下面的代码段就是编写了file2matrix()函数,将文本文件转换为矩阵。
程序清单:

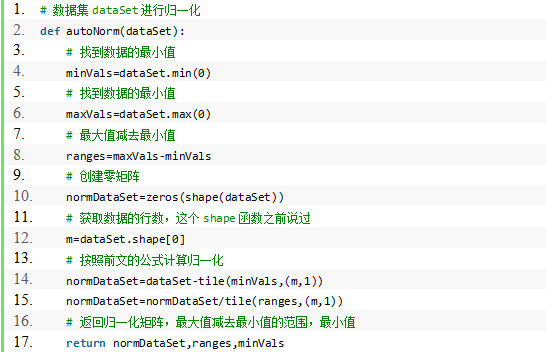
3. 归一化数值
当度量标准不一样时,如果没有将数据归一化,可能导致数值大的特征在评价中起较大作用,而实际这几个特征的重要性是一样的。
所以为了特征重要性的评判,我们要进行数据归一化。归一化方式有很多,我们一般用:
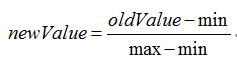
程序清单:
4. 分类器的测试代码
用测试数据集来测试算法的分类准确度,这里会用到刚才创建的几个函数。
程序清单:

以上构建的函数是KNN算法实现的主要框架,我们现在调用的很多算法包很多也是按照上述方式构建出来的。
当然,scikit-learn中的KNN算法肯定是优化版,速度会快很多,但核心思想却是一样的。
至此,我们完成了KNN算法原理和主要代码的学习。KNN算法是分类数据最简单最实用的方法,有广泛的应用。本篇写的比较概括,目的在于抛砖引玉,希望大家可以挖掘出KNN算法更多的东西来交流探讨。
下一节我们将进行决策树算法的学习。
声明
以上均为本人自学整理所得,如有错误,欢迎指正,有任何建议也欢迎交流,让我们共同进步!转载请注明作者与出处。
原理部分主要来自于《机器学习》—周志华,《统计学习方法》—李航,《机器学习实战》—Peter Harrington。代码部分主要来自于《机器学习实战》。代码部分用Python3实现。