这篇文章转载自我在知乎的文章
摘要
-
CART决策树
-
决策树的剪枝技术
-
Bagging与随机森林
-
决策树中缺失值的处理
-
决策树代码
注:对于学习《机器学习实战》的读者,本节代码部分对应第九章“树回归”。
CART决策树
可能有读者会问,为什么同样作为建立决策树的三种算法之一,我们要将CART算法单独拿出来讲。
因为ID3算法和C4.5算法采用了较为复杂的熵来度量,所以它们只能处理分类问题。而CART算法既能处理分类问题,又能处理回归问题。
对于分类树,CART采用基尼指数最小化准则;对于回归树,CART采用平方误差最小化准则。
1. CART分类树
CART分类树与上一节讲述的ID3算法和C4.5算法在原理部分差别不大,唯一的区别在于划分属性的原则。CART选择“基尼指数”作为划分属性的选择。
Gini指数作为一种做特征选择的方式,其表征了特征的不纯度。
在具体的分类问题中,对于数据集D,我们假设有K个类别,每个类别出现的概率为Pk,则数据集D的基尼指数的表达式为:
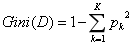
我们取一个极端情况,如果数据集合中的类别只有一类,那么:
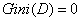
我们发现,当只有一类时,数据的不纯度是最低的,所以Gini指数等于零。Gini(D)越小,则数据集D的纯度越高。
特别地,对于样本D,如果我们选择特征A的某个值a,把D分成了D1和D2两部分,则此时,Gini指数为:
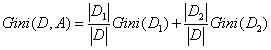
与信息增益类似,我们可以计算如下表达式:
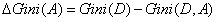
即以特征A划分后,数据不纯度减小的程度。显然,我们在做特征选取时,应该选择最大的一个。
2. CART回归树
我们首先要明白回归树与分类树的区别。如果决策树最终的输出是离散值,那么就是分类树;如果最终的输出是连续值,那么就是回归树。
我们在之前做分类树的时候,用了熵、Gini指数等指标衡量了离散数据的混乱度。那我们用什么来衡量连续数据的混乱度呢?很简单,采用平方误差准则。首先我们计算所有数据的均值,然后计算每条数据的值到均值的差值,平方后求和:
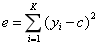
其中,一共有K条数据,均值为c,第i条数据的值为yi。
那我们怎么对输入空间进行划分呢?
选择第j个特征和它的取值s作为切分变量和切分点,并划分为两个区域:
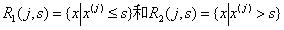
然后寻找最优切分变量j和最优切分点s,使得:
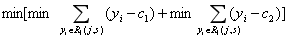
其中,yi为R1区域中第i条数据的目标值,c1为R1区域中目标的均值。
伪代码如下:

进行递归之后,我们的回归树就建好了。具体实现过程,后面附有代码。
回归树建好后,我们采用的是用最终叶子节点的均值或者中位数作为预测输出结果。
注:用树来对数据进行建模,除了把叶子节点简单设为常数值之外,我们也可以把叶节点设为分段线性函数,这样就建立了模型树。由于其原理和回归树相差不大,这里不展开叙述,想要深入的读者可以参考《机器学习实战》P170.
剪枝
决策树算法中很容易发生“过拟合”现象,导致算法的泛化能力不强。目前,解决决策树“过拟合”现象的主要方法有两种:1.剪枝技术,2.随机森林算法。
剪枝技术分为“预剪枝”和“后剪枝”。预剪枝是指在决策树生成过程中,对每个节点在划分前先进行估计,若当前节点的划分不能带来决策树泛化能力的提升,则停止划分并将当前节点标记为叶子节点;后剪枝是先从训练集中生成一颗完整的决策树,然后自底向上地对非叶节点进行考察,若将该节点对应的子树替换为叶子节点能够带来决策树泛化能力的提升,则将该子树替换为叶子节点。
以分类问题为例,上一节讲过,我们将叶子节点的类别标记为叶子节点中训练样例数最多的类别。
那我们怎么判断决策树泛化能力是否提升呢?我们通常情况可预留一部分数据用作“验证集”,我们判断的依据就是剪枝前后这个节点在验证集上的分类正确率。如果剪枝后正确率上升,那么这个节点可以进行剪枝;反之,则不对该节点进行剪枝。注意一下,如果剪枝前后正确率不变,根据奥卡姆剃刀准则,我们一般情况下是选择进行剪枝操作,因为“如无必要,勿增实体”。
剪枝技术小结
(1) 对于预剪枝来讲,它使得决策树的很多分支都没有展开,这不仅降低了过拟合的风险,还显著减少了决策树的训练和预测时间开销。但是另一方面,有些分支的当前划分虽然不能提升泛化性能、甚至可能导致泛化性能暂时下降,但是在其基础上的后续划分却有可能导致性能显著提高,这给预剪枝带来了欠拟合的风险;
(2) 对于后剪枝来讲,通常情况下,它比预剪枝决策树保留了更多的分支。后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树,但是其训练时间开销比未剪枝决策树和预剪枝决策树大得多。
Bagging与随机森林
Bagging和随机森林算法属于集成学习中的一种方法,可以解决决策树过拟合问题。它们的主要思想就是建立多个分类器(如决策树),以降低过拟合的风险。
1.Bagging
Bagging算法是并行式集成学习中最著名的代表。Bagging算法的基本流程如下:
(1) 从训练样本集中有重复地选中n个样本
(2) 在所有属性上,对n个样本建立一个分类器
(3) 重复以上两步m次,即可获得m个分类器
(4) 将测试数据放到m个分类器上,最后根据这m个分类器的投票结果,决定数据属于哪一类
2.随机森林算法
随机森林算法是在Bagging基础上的扩展,进一步在决策树的训练过程中引入了随机属性选择。
基本流程如下:
(1)从训练样本集中有重复地选中n个样本
(2)在所有属性中随机选取K个属性,选择最优划分属性,对n个样本建立一个分类器
(3)重复以上两步m次,即可获得m个分类器
(4)将测试数据放到m个分类器上,最后根据这m个分类器的投票结果,决定数据数据属于哪一类
一般取k=logd,d是所有属性的个数,如果k=d,则Bagging算法和随机森林算法就是一样的。
其实随机森林算法中的“随机”有两层含义:1.从训练样本集中有重复随机选中n个样本;2.每次在所有属性中随机选取k个属性。
决策树中缺失值的处理
在现实任务中我们常常会遇到不完整的样本,即样本中的某些属性值缺失,这时候我们怎么充分利用这些数据来建立决策树呢?
由于这部分内容与决策树算法本身无关,属于实际操作上的技巧,这里不展开叙述。想要深入了解的读者可以参考周志华老师《机器学习》P85.
至此,决策树理论部分到此就结束了,下面是回归树和模型树的具体实现代码与解释。
代码实现与解读
1. CART算法的实现代码
程序清单:


2. 回归树的切分函数
程序清单:


3. 回归树剪枝函数
程序清单:


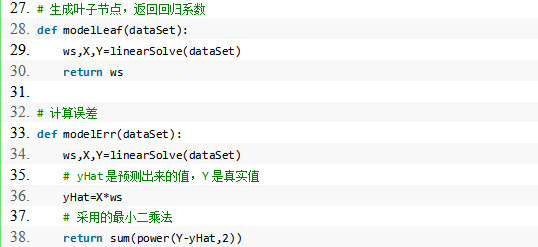
4. 模型树叶节点生成函数
程序清单:

至此,通过两节内容,完成了决策树算法的学习,希望能给大家一点帮助。
下一节我们将学习朴素贝叶斯分类。
声明
最后,所有资料均本人自学整理所得,如有错误,欢迎指正,有什么建议也欢迎交流,让我们共同进步!转载请注明作者与出处。
以上原理部分主要来自于《机器学习》—周志华,《统计学习方法》—李航,《机器学习实战》—Peter Harrington。代码部分主要来自于《机器学习实战》,代码用Python3实现,这是机器学习主流语言,本人也会尽力对代码做出较为详尽的注释。