这篇文章转载自我在知乎的文章
摘要
-
支持向量机简介
-
拉格朗日乘子法
-
对偶问题
这几天学习支持向量机的原理部分,发现比之前的算法难了很多。查了很多资料,有了自己的一些理解,希望能给大家一些帮助。
支持向量机(support vector machines,SVM)是一种二分类模型,应用十分广泛,当然其也可以用于回归问题。这一节主要梳理支持向量机的基本概念、拉格朗日乘子和对偶问题。下一节主要梳理线性支持向量机、非线性支持向量机、核函数、SMO算法和支持向量回归的问题。
支持向量机
支持向量机(SVM),最主要的用途就是用作分类。如下图所示(图片来自于网络,侵删),有圆形和方形两种类别,我们希望找到一个划分超平面,将两种类别划分开。
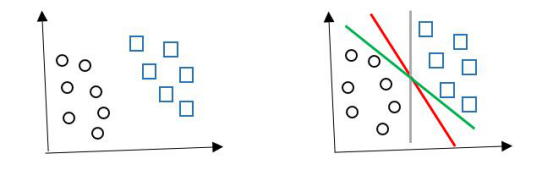
但是如右上图所示,划分超平面的方式有很多,我们应该努力寻找哪一个呢?
直观上来讲的话,我们应该寻找最中间红色的那一个划分超平面,因为其对样本的鲁棒性比较好,对于未知示例的泛化能力较强。
假设我们给定一个样本空间的训练集:
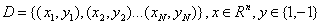
其中x为样本特征,y为类别标记,y=1为正例,y=-1为负例。
我们希望找到一个分离超平面,其线性方程为:
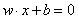
w={w1,w2…,wN}是法向量,d是截距。w*x是内积。确定了w和b,分离超平面也就随之确定了。
函数间隔与几何间隔
下面给大家介绍两个概念,函数间隔和几何间隔。
函数间隔:对于给定的训练样本集D和超平面(w,b),定义样本点(xi,yi)到超平面的函数间隔为:
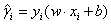
定义超平面(w,b)到训练集D的函数间隔为所有样本点的函数间隔的最小值,即:
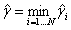
函数间隔总是正数,因为当样本为负类时,yi和(w*xi+b)都小于零。
函数间隔表示了分类预测的相对正确性和确信度,因为(w*xi+b)越大,说明样本点离分离超平面越远,分类正确的可能性也就越高。
同时我们需要格外注意一下,对于同一个样本点和分离超平面,函数间隔可能会不一样。这句话应该怎么理解呢?我们如果成比例地改变系数w和b,比如把w和b变成2w和2b,分离超平面没有发生任何改变,但是对于样本点(xi,yi),函数间隔却变成了原来的两倍。所以函数间隔只能表示分类预测的相对正确性和确信度。
几何间隔
几何间隔我们可以简单理解为实际的距离。
样本空间中点(xi,yi)到超平面的几何间隔为:
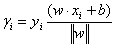
这是高中学过的几何知识。
定义超平面(w,b)到训练集D的几何间隔为所有样本点的几何间隔的最小值,即:
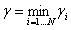
函数间隔和几何间隔有如下关系:
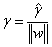
当$||w||=1$时,两者相等。如果超平面参数w和b成比例的改变(超平面没有改变),函数间隔也按此比例改变,而几何间隔不变。
间隔最大化
SVM的基本思想就是求解能够正确划分数据集并且几何间隔最大的分离超平面。通俗讲就是样本点到分离超平面的最小间隔的最大化,即对最难分的样本点(离超平面最近的点)也有足够大的确信度将它们分开。
可以表示成如下最优化问题:
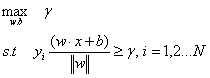
即我们希望最大化数据集的几何间隔。这时我们将几何间隔和函数间隔进行转换,得:
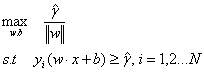
函数间隔的取值并不影响最优化问题的解。这句话是下面化简步骤的核心,怎么理解这句话呢?

所以优化问题转换成如下:
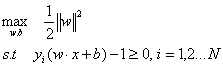
这就是支持向量机的基本优化类型,这是一个凸二次优化问题。
对上述优化问题求解,得到最优解w和b,就得到了分离超平面:
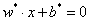
并且这个最大间隔分离超平面是存在且唯一的。详细的证明请见《统计学习方法》P101。
这个问题中的w和b应该怎么求解?下面介绍拉格朗日乘子法和对偶问题。
拉格朗日乘子法
拉格朗日乘子法是一种寻求多元函数在约束条件下的极值的方法。通过引入拉格朗日乘子,可以将带约束条件的优化问题转换为不带约束的优化问题。
这部分其实在高数部分已经学习过,给大家温习一下。
有优化问题如下:
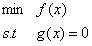
我们构造如下函数:
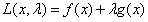
其中,λ称为拉格朗日乘子。我们进行如下计算后即可求得极值:
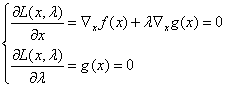
通过计算我们就可以求得极值点x*和λ。
那这个定理是怎么来的呢?
首先,由上述优化问题,我们可以得到两个结论:

第一点比较好理解,关于第二点的结论可能很多人不是很能理解,给大家附上链接https://www.zhihu.com/question/38586401,这里面讲的很清楚,我不赘述。
由上述两个结论,即可得两个梯度的方向必相同或相反,即存在λ≠0使得:
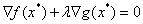
这时候就得到了拉格朗日函数:
这就是拉格朗日乘子法的由来。
对偶问题
但有些时候,优化问题并不是那么简单,比如有如下优化问题:
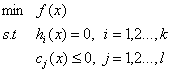
称此优化问题为原始问题,当有不等式优化时我们应该怎么解?
我们现在需要找到优化问题的下界,即:
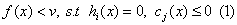
若方程(1)无解,则v就是原问题的一个下界,而最大的v就是问题的最优解。而问题(1)可以等价为:
存在λ≥0,使得问题(2)无解:
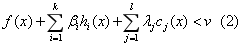
令:
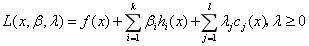
而方程(2)无解的充要条件是:
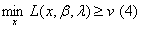
我们希望找到最优的下界,所以:
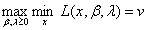
所以原问题的对偶问题是:
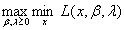
我们求得了原始问题的对偶问题。不论原始问题的凸性如何,对偶问题一定是凸问题。我们假设原始问题的最优值为p,对偶问题的最优值为d。
因为:
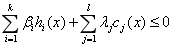
所以:
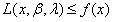
所以:

所以:
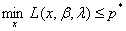
所以:
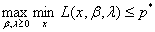
即:
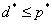
上述称为弱对偶性,对偶问题提供了原问题最优解的一个下界。
那什么时候对偶问题的解和原始问题的解相同呢?即d=p呢?给出两个定理:
定理1:对于原始问题和对偶问题,假设函数f(x)和Cj(x)是凸函数,hi(x)是仿射函数,并且不等式约束Cj(x)严格成立,则存在x,β,λ,使得x是原始问题的解,β,λ是对偶问题的解,并且
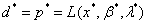
定理2:对于原始问题和对偶问题,假设函数f(x)和Cj(x)是凸函数,hi(x)是仿射函数,并且不等式约束Cj(x)严格成立,x和β、λ*分别是原始问题和对偶问题的解的充分必要条件满足下面(KKT条件):
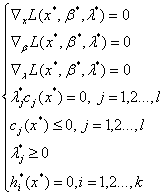
通过求解上式就可以求得原始问题的最优解。将拉格朗日乘子法和对偶问题法应用到SVM中也就可以得到w和b,最终得到分离超平面:
以上就是支持向量机原理的第一部分,推导部分有点长,希望大家可以自己手动推导一遍。下次一起学习线性支持向量机、非线性支持向量机、核函数、SMO算法和支持向量回归的问题。
声明
最后,所有资料均本人自学整理所得,如有错误,欢迎指正,有什么建议也欢迎交流,让我们共同进步!转载请注明作者与出处。
以上原理部分主要来自于《机器学习》—周志华,《统计学习方法》—李航,《机器学习实战》—Peter Harrington。代码部分主要来自于《机器学习实战》,代码用Python3实现,这是机器学习主流语言,本人也会尽力对代码做出较为详尽的注释。